In Stock — Ships Within 7 Days
8× Intel Arc Pro B70 32GB
AI Inference Server
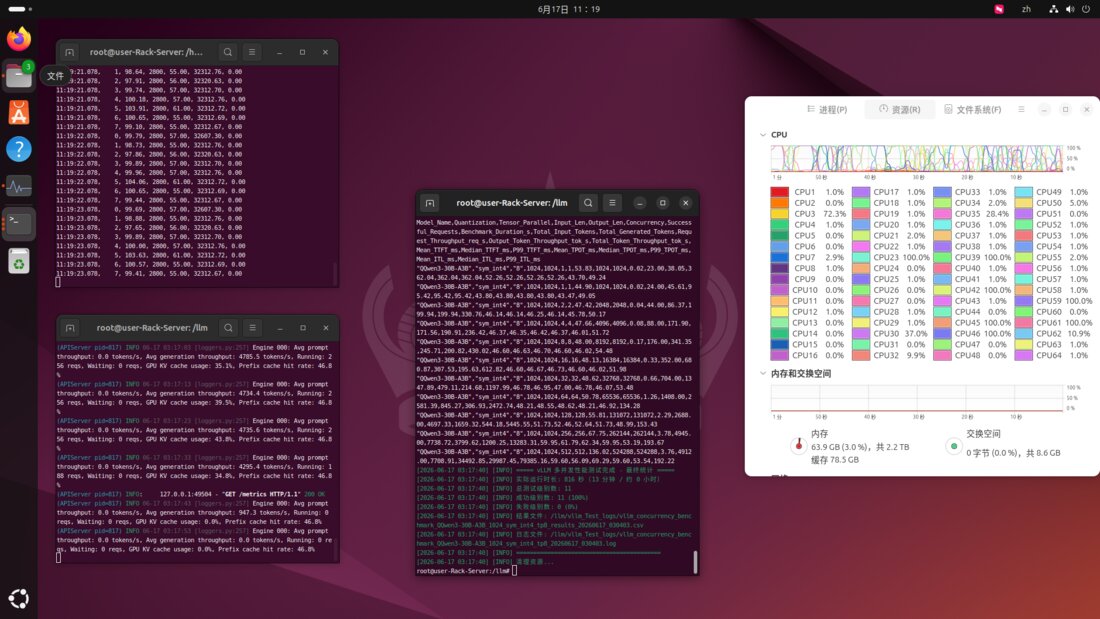
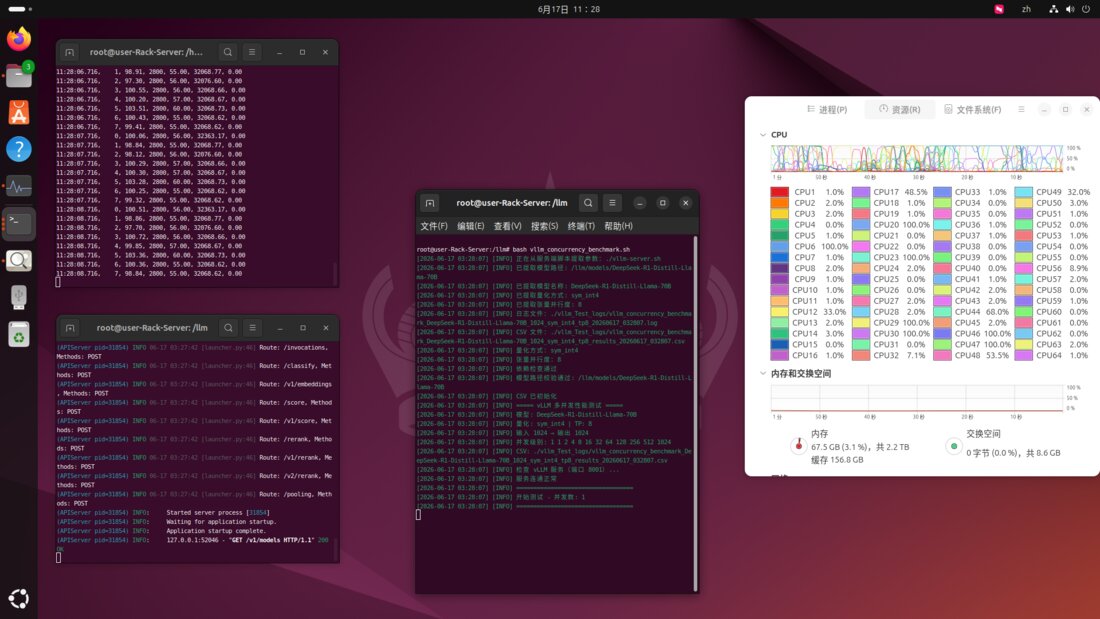
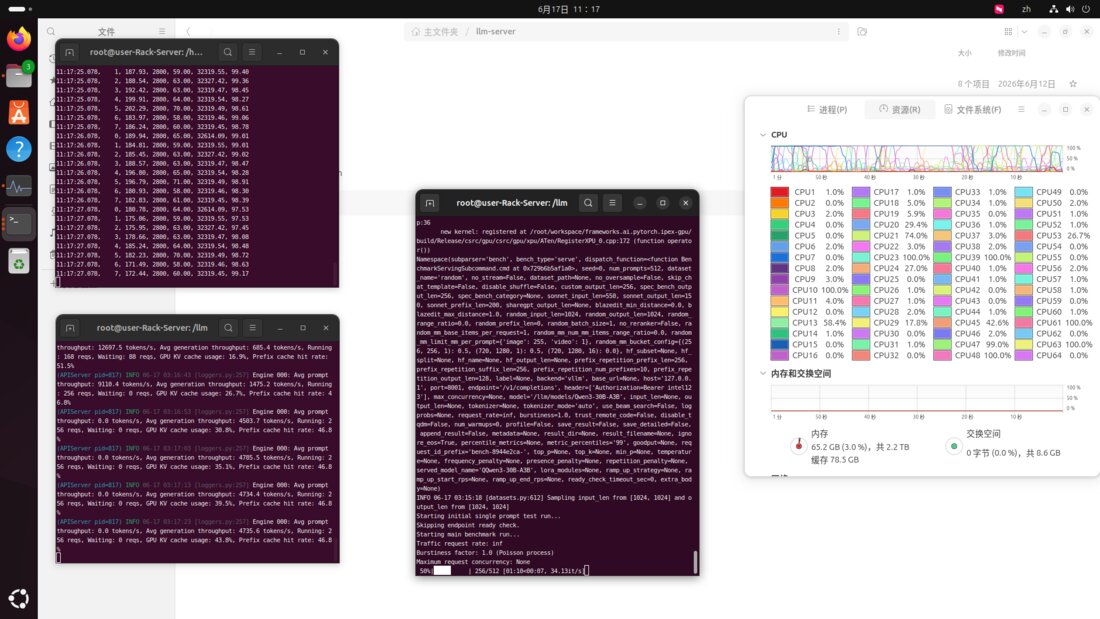
Run DeepSeek-R1 70B, LLaMA 3, and Qwen at production speed. Performance matches RTX 5090D — at one-third the cost. Purpose-built for teams deploying LLMs on-premise.
$0
USD / unit

256GB VRAM
8× B70 GPU
10.8kW PSU